成果
本篇文章从一个全新的角度来解决Few Shot Segmentation任务。先前的小样本分割模型都是遵循先由support图像中学习特征(prototype),在用prototype(s)来引导query图像分割的范式。然而这种做法将匹配和分割融合到一起,提升了网络的学习难度。
本篇文章的提出了“先分割,后匹配”的范式,首先使用类无关的分割器将query图像分割出多个先验掩码(mask proposals)。之后由support图像引导的进行掩码匹配,将相关的掩码合并得到最终结果。
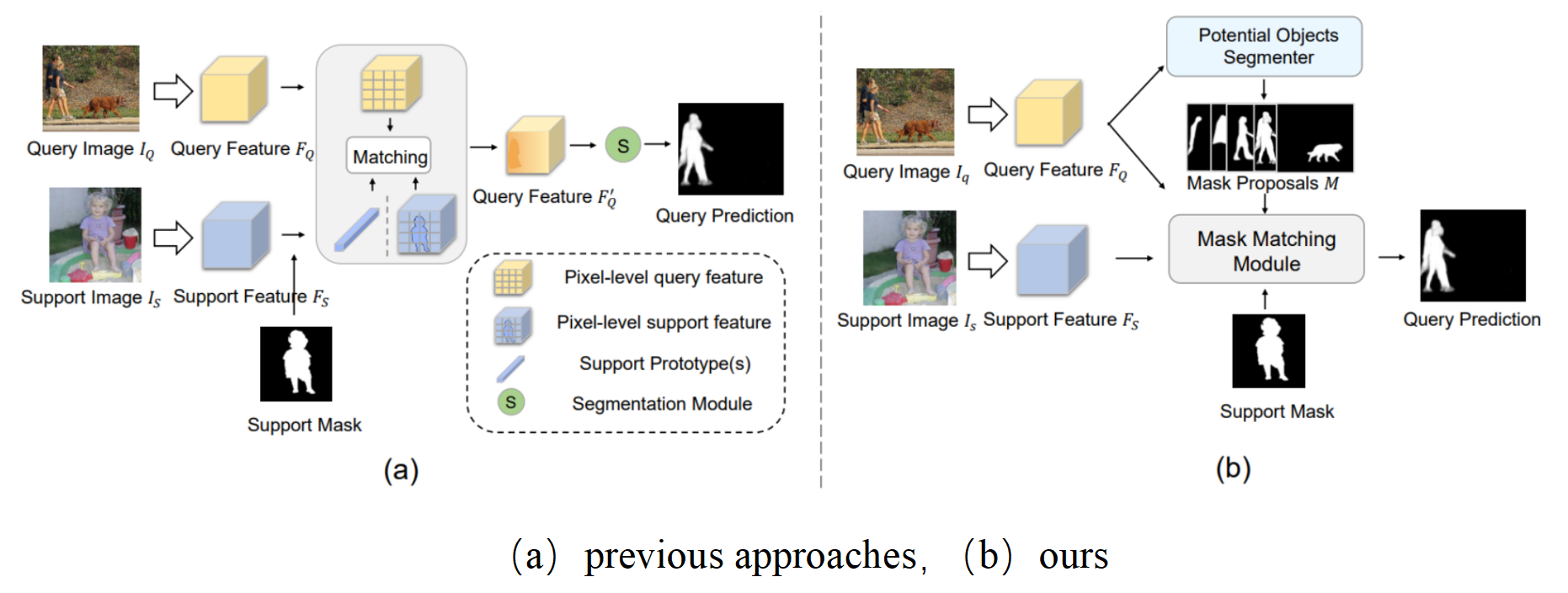
优势:(1)MM-Former遵循“先分割,后匹配”的范式,可为query图像生成高质量的掩码。(2)prototype(s)仅需引导同类别掩码的匹配,而非像素级分割,很大程度降低了网络的学习难度。
基于匹配和分割解耦的设计,降低了网络的学习难度,因此相比先前的SOTA方法CyCTR和HSNet,很大程度上减小了训练时间和训练内存消耗。

文章主要的贡献
(1)提出了新的Few Shot Segmentation任务的范式
(2)提出了两阶段小样本分割框架MM-Former,可以有效地将support样本与一组先验掩码进行匹配来获得分割结果。
(3)在COCO和PASCAL上取得了SOTA的结果
论文中的模型结构如下:
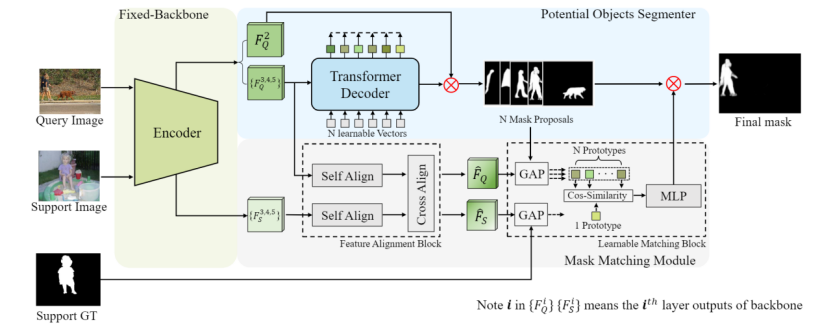
这篇文章遵循Mask2Former的设定,采用标准的Transformer结构,将backbone经过MSDeformAttn后的特征与N个可学习向量进行cross attention。由N个向量引导先验掩码产生。这种先验掩码和目标检测、零样本分割任务中的先验框类似,具有很强的泛化性,可对训练集未出现过的类别(novel class)产生准确分割。
这里需要注意的一点是,先验掩码的产生并不涉及support和query之间的特征交互,仅由query图像通过backbone+ Potential Objects Segmenter(POS)模块产生。
这一模块将support样本提取出的prototype和query样本通过先验掩码提取出的N个prototypes进行匹配,来确定最终的分割结果。这种匹配仅在prototype之间进行,不需要考虑像素级的分割,因此相比于先前模型将匹配和分割融合的做法,很大程度上降低了网络学习的难度。
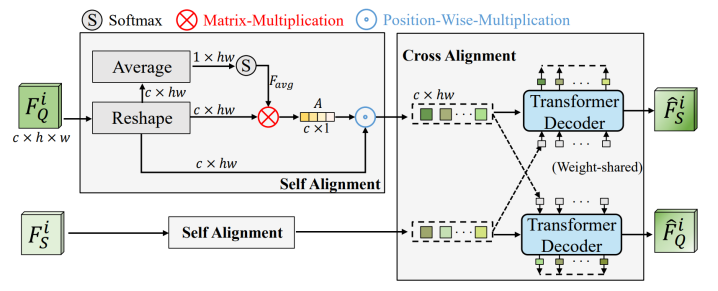
Feature Alignment Block: 将support样本和query样本由backbone提取出的特征进行对齐。分为特征自对齐(Self Alignment)和特征互对齐(Cross Alignment)两部分,如下图所示。Self Alignment在channel维度平滑了特征,强调了重要的通道,抑制了不重要的通道。Cross Alignment使support和query的同类特征趋于一致。
Learnable Matching Block: 通过mask global pooling的方式分别得到support的prototype和query的N个prototypes,并计算二者之间的余弦相似度,在经过MLP层预测得到最终匹配结果。
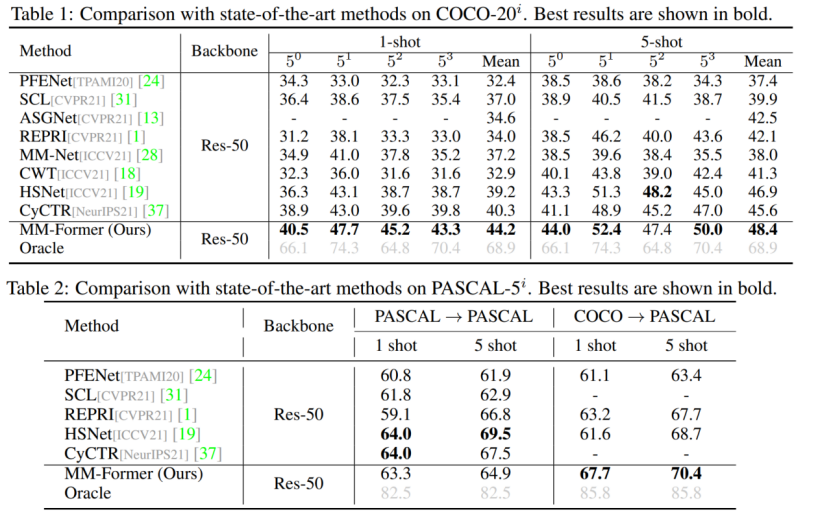
其中Oracle结果为生成N个先验掩码后直接使用groundtruth选择一个IoU最高的掩码作为分割结果。Oracle和最终结果之间的差距(~20mIoU)表明MM-Former还有很大的潜在提升空间。
(a)对Mask Matching Module各模块进行消融,(b)对特征对齐模块FAB的插入位置进行消融,(c)对两阶段的训练策略进行消融
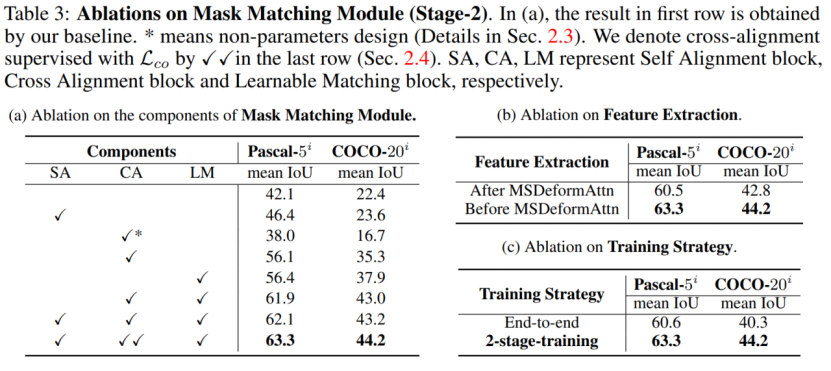
(a)对POS的分类器进行消融,(b)对先验掩码数量进行消融。
MM-Former在使用COCO训练时表现出很好的迁移性能,但在使用PASCAL训练中表现相对较差。这篇文章对此现象进行了深入研究
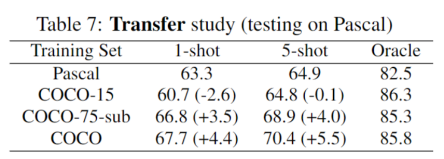
这篇文章使用COCO数据集中的15个PASCAL训练类别的所有训练样本来训练MM-Former。在这种情况下,训练样本大约为PASCAL训练集的9倍(COCO-15)。当训练类别数量有限时,更多的培训数据并不会提升性能(60.7mIoU vs 63.3 mIoU)
这篇文章从COCO数据集中的75个类别(不包括测试类别)随机抽取和PASCAL数据集相同数量的训练图像(大约6000张),来训练MM-Former(COCO-75)。当使用同等数据量进行训练时,更多的类别会带来更好的匹配性能(66.8mIoU vs 63.3mIoU)。
总之,训练类别的数量决定了匹配模块的性能。这一发现符合Few Shot任务和Meta Learning的动机。当训练类别的数量有限时,会影响匹配模块的性能。
增量学习在图像分类任务中已经得到了广泛研究,并在缓解灾难性遗忘的问题上取得了一些成果。但在类增量语义分割这一任务上,由于背景类的语义转移(semantic shift of the background class, 即模型在过去学到的一些概念被分配到当前训练中的背景类中的情况)存在,类增量语义分割任务仍然具有挑战。
本文为解决背景类的语义转移问题,提出了一种名为MicroSeg的新颖而有效的方法,该工作基于“在背景中具有显著对象性的区域很可能属于过去或者未来的概念”的思想,通过生成类别无关的先验掩膜(mask proposals, 下同)来挖掘这些区域,并在优化阶段对它们进行聚类与分配新的标签,以进行更好地训练。相对于之前最先进的方法(SSUL)通过显著性检测来寻找重点区域,MicroSeg关注到了图像中的几乎所有thing和stuff,并获得了更好的分割结果。

本文的贡献如下:
(1)提出了MicroSeg,通过mask proposals,使得在背景中的概念的分布特征可以被模型更好地感知,有效缓解由背景类的语义转移引起的灾难性遗忘问题。
(2)在两个基准数据集的多个增量场景下取得了最先进的效果,且在增量步骤更多的困难场景下,相对之前工作的性能提升更加明显。
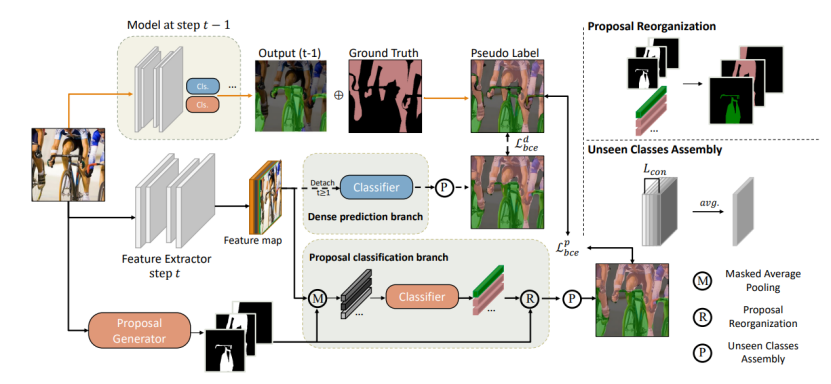
Models: 本文中,语义分割的模型由两部分组成:Feature Extractor和Classifier,特别地,对于第t(t-1)训练阶段,会使用(t-1)训练阶段的模型来对于当前的训练过程进行监督。
Proposal generator: 本文中,通过Mask2Former来生成mask proposals,所有的mask proposals没有交集。
Proposal classification branch: 在这个分支中,Feature Extractor输出的图像特征会和mask proposals进行掩膜平均池化(mask average pooling)操作以获得proposals所对应的原型表示,之后通过Classifier对于这些原型表示进行分类,以得到mask proposals对应的类别标签。接下来,Proposal Reorganization操作将proposal的分类映射回原图像上,并得到语义分割的结果。
Dense prediction branch: 密集分割分支对于Feature Extractor输出的图像特征进行像素级的预测,得到语义分割的结果。该分支仅在t=0时使用,用于保证模型早期训练的效果。
为了有效利用模型在过去学习到的概念,本工作通过上一学习阶段的模型的预测,以及ground truth通过以下规则生成伪标签,在优化过程中为模型提供更加合理的监督信息。通过对于标签的重建,减轻了背景类的语义迁移现象。
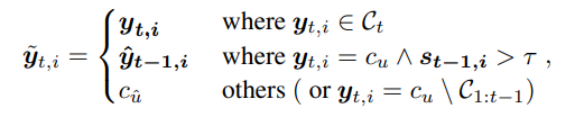
直观地,对于ground truth的背景区域中,过去模型判定为前景,且有较大置信度的像素,会在伪标签中被标注为前景;而背景中的其他区域则标注为未见(unseen)类别,通过Micro 机制进行进一步细分和消解。
在Label remodeling中,本文对背景中潜在的各种概念进行表征,并缓解背景类的语义迁移的问题。但即使是未见类别也可能包括若干不同的thing或stuff,因此,本文进一步对其进行消解,将其分为不同部分,其中每个部分都可以视为一个未见概念的特征中心。
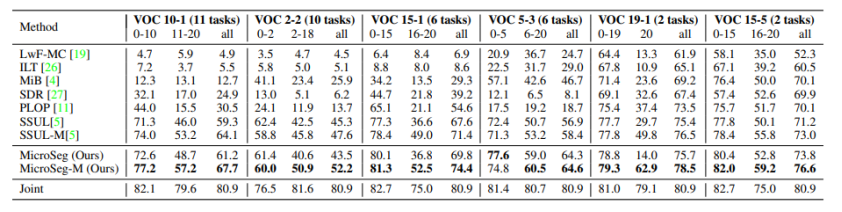
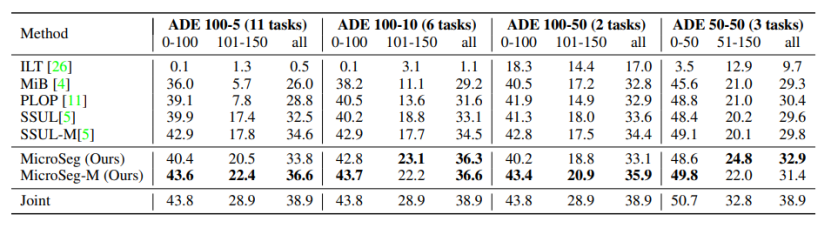
以下是本文提出的MicroSeg在两个基准数据集Pascal VOC 2012 和ADE20K上不同增量场景下的实验结果,其中MicroSeg-M是储存了部分样本用于训练的设定,该设定的提出是为了和之前的工作(SSUL-M)进行公平比较。
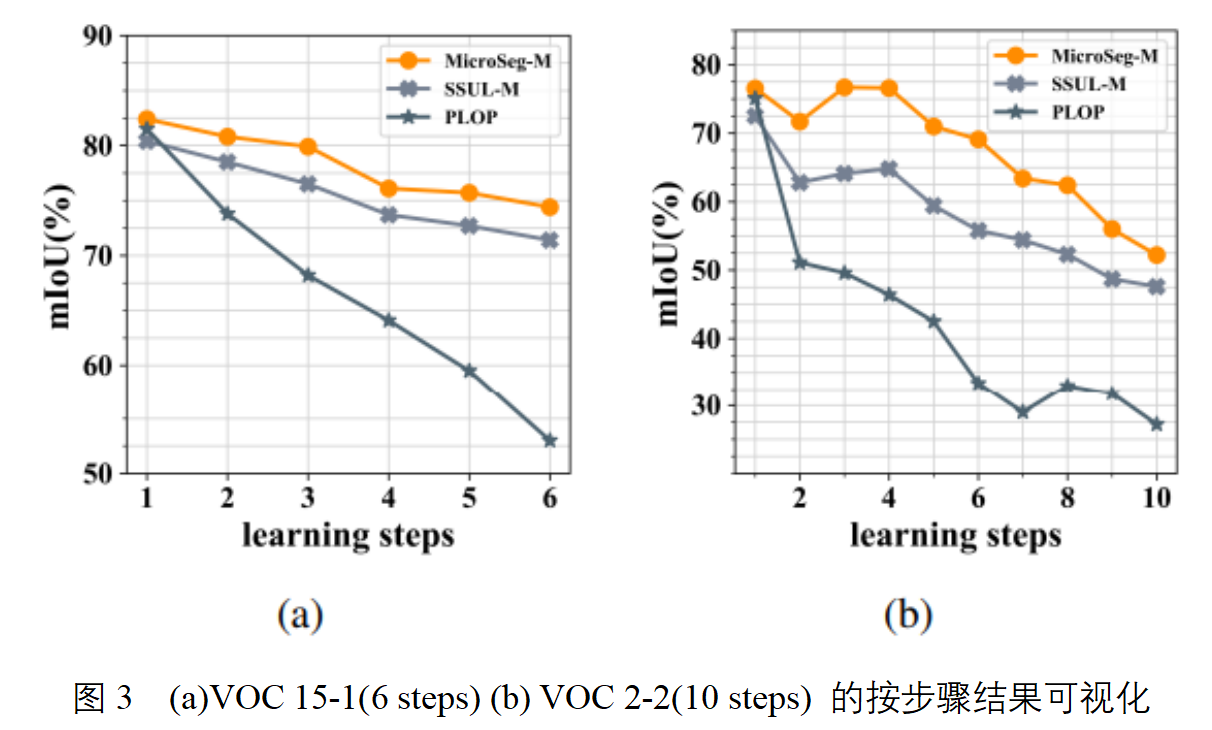
以下是不同增量场景下的实验结果按步骤可视化与之前最先进工作的比较:(a)VOC 15-1(6 steps), (b) VOC 2-2(10 steps)。本文提出的MicroSeg相对之前的方法在相同学习条件下遗忘程度更低,性能更好。
下图是Micro机制的定性分析。从‘cluster’一列中可以看出,在无监督的条件下,通过Micro机制很好地将背景部分分割成了合理的几个区域。这种分割将有助于新知识的学习,以及防止新概念对于旧知识的冲击。

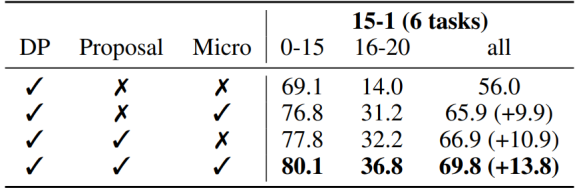
下表是对于几个主要模块DP (dense prediction branch), Proposal (proposal classification branch), Micro (Micro mechanism)的消融实验,能够比较直观地体现每个组成部分带来的性能提升。
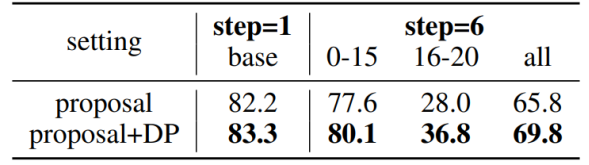
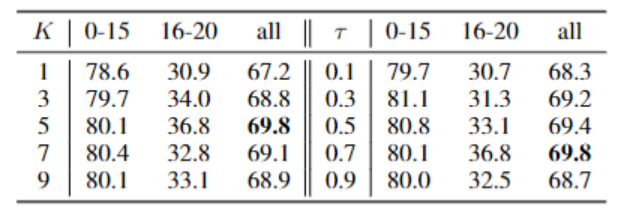
下表是对于超参数(Micro机制的K,标签重建中的阈值τ)的消融实验,可以观察到本问题提出的方法对于超参数的选择并不很敏感。
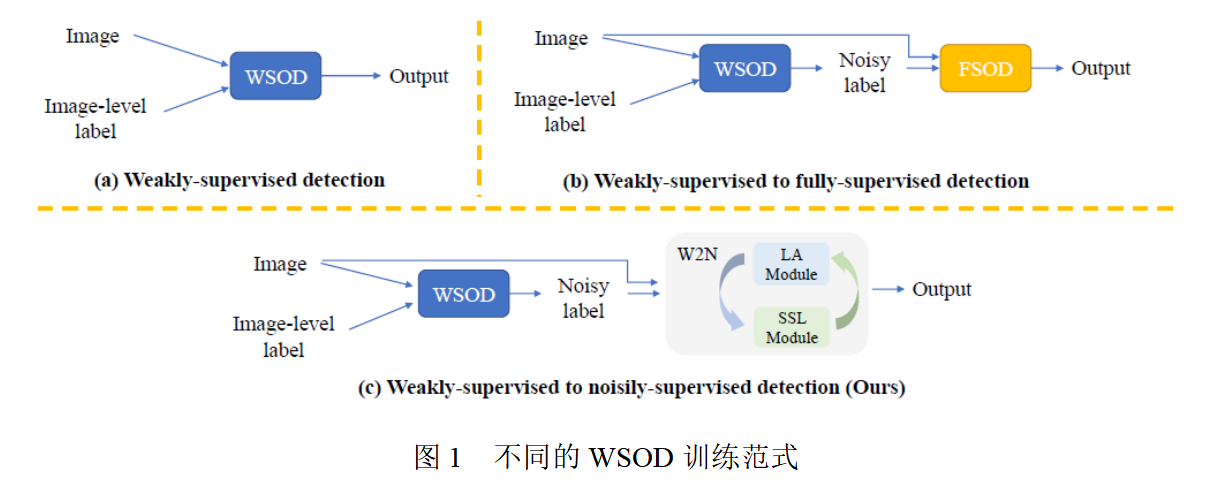
弱监督物体检测任务(WSOD)旨在仅利用图像级别的类别标签来训练一个检测器。近年来,一些弱监督检测方法试图从原始的WSOD模型中挑选高质量的伪标注来提升模型性能。然而,这些方法仅仅根据图片及的线索,将带有伪标注的训练集数据集划分为有标签集和无标签集,而忽略了每一个检测框的分类信息和定位信息,因此信息没有得到充分利用。在本工作中,本文提出将弱监督信号转化为带噪监督信号的目标检测算法(W2N),该算法包含两个迭代训练的子模块。本文的算法充分考虑了每一个检测框具有的信息,并提出了一个正则化损失来缓解WSOD会集中注意到"discriminative part"的问题。实验结果显示,本文的方法在PASCAL VOC, COCO等数据集上都达到了SOTA。图1为不同WSOD方法的训练范式。
本文的主要贡献如下:
(1)本文提出了一种新的多阶段WSOD范式,它将多阶段弱监督物体检测问题建模为噪声标签物体检测问题求解,以减少低质量的伪标签对模型的负面影响。
(2)为了解决带噪声标签物体检测的训练问题,本文提出了一个迭代学习框架,包括定位适应模块和半监督学习模块,从而提高了伪标签的质量并提升了检测器的性能。
(3)本文在不同基准数据集上验证了本文的方法的有效性。实验结果表明,本文的方法可以有效提升各个单阶段WSOD模型的性能,并在WSOD任务上达到了到SOTA。
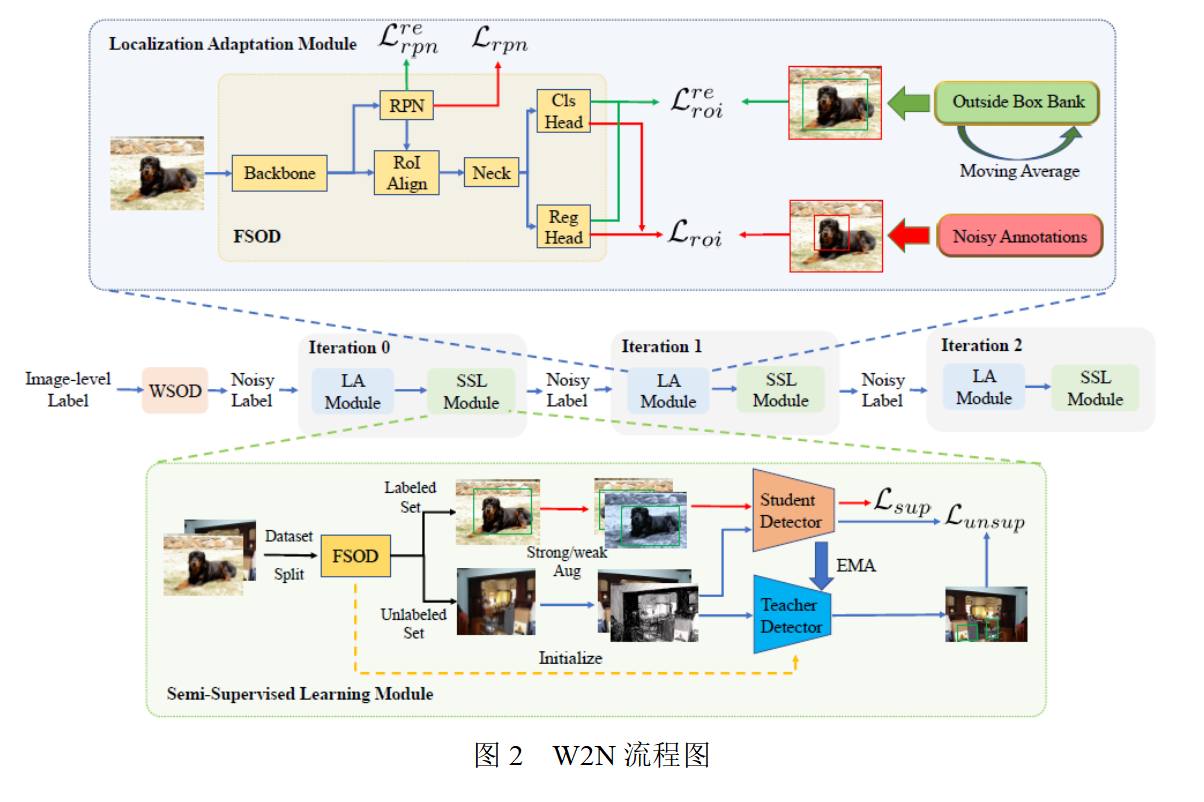
首先在弱监督数据集上训练一个基础的弱监督检测网络。 接着利用训练好的弱监督检测网络,对训练集标伪标签。本文称这个带伪标签的训练集为“带噪声标注的数据集”。为了在这样的噪声数据集上训练物体检测器,本文提出了一个新的训练框架W2N,它循环迭代执行定位适应模块和半监督学习模块,以产生更加准确的伪标签,并利用更新后的伪标签监督训练一个更好的物体检测器。整体训练流程如图2所示。
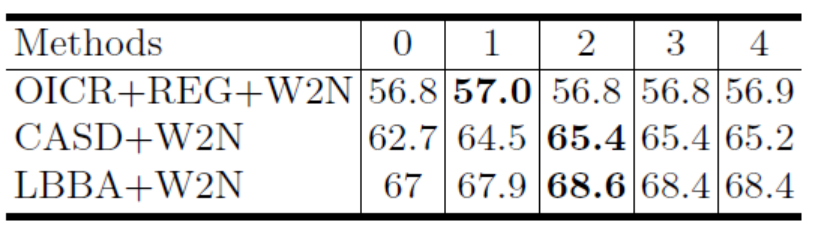
首先在弱监督数据集上训练一个基础的弱监督检测网络。 用该检测网络在训练集上预测检测框,并将输出的分类分数低于给定阈值的检测框删除,剩下的检测框作为初始的伪标签。在本文中,分别采用OICR+REG,CASD和LBBA作为基础的弱监督检测网络。
本文提出了一个训练框架W2N,它在定位适应模块和半监督学习模块之间反复进行迭代。以下各小节将详细说明这两个模块。

对于位于discriminative part的伪监督框,在训练时,在其外侧生成一个预选框,考察该预选框位置的变化。本文发现,在训练的初始阶段,该预选框首先会往物体所在的位置移动;然而随着训练的进行,预选框最终会靠近该内部的伪监督框,如图3所示。本文利用这个现象,将该预选框中间回归的结果保存,作为额外的监督信息,计算正则化loss训练网络模型。
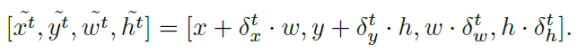
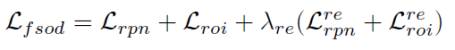
在该模块中,本文设计了一个混合级数据集划分方法以及一个基于伪标签的半监督训练算法。
在SoS中,数据集划分以图片作为最小单元。本文认为,由于图片中往往存在多个物体和多个伪监督框,因此以伪监督框本身为划分单元更能充分利用高质量的伪监督、忽略低质量的伪监督,因此提出了实例级划分方法。
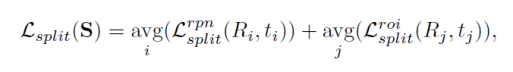
在该方法中,根据每个伪监督框上累计的loss的大小,将loss较低的伪监督框保留,剩余的部分删去。
本文发现存在部分伪监督框的分类信息准确,但定位信息不准;相似的,存在部分伪监督框定位信息准确,但分类信息不准。为了更加充分利用每个伪监督框准确的信息,本文进一步提出双任务实例级划分方法。具体而言,对于每个伪监督框,分别计算其分类loss和回归loss,分别按照其对应任务的loss的值对其划分。对于分类信息准确而定位信息不准的伪监督,在后续的半监督检测流程时,只用其训练分类;反之,只利用其训练回归。
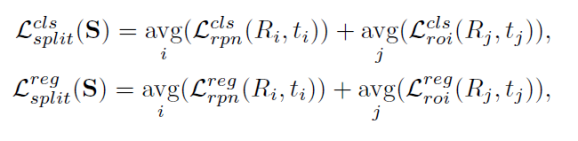
本文采用unbiased teacher作为半监督物体检测框架。将上述数据集划分得到的clean set作为labeled set,noisy set作为unlabeled set,执行半监督检测流程。
本文分别以OICR+REG,CASD和LBBA作为基础的弱监督检测模型来搭建提出的W2N训练方法,以下是在PASCAL VOC 2007上的实验结果
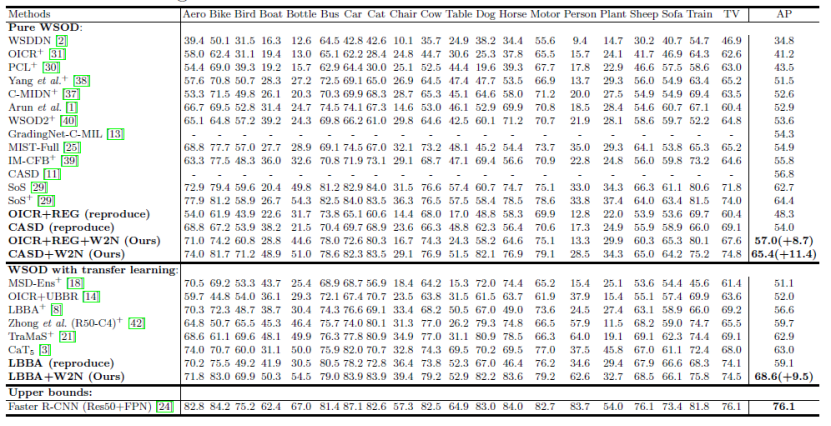
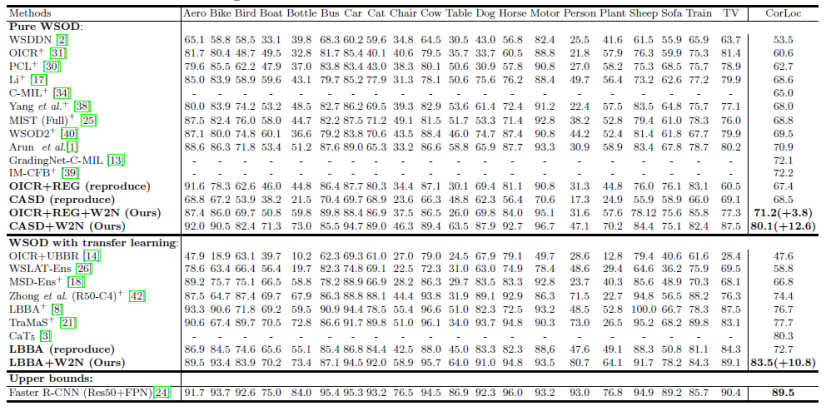
实验结果表明,本文提出的W2N训练方式可以有效提升基础弱监督检测网络的性能,性能越了其他WSOD方法。

图4中,第一行为LBBA的可视化结果,第二行为LBBA+W2N的可视化结果,第三行为真实的标注框。
下表展示了本文提出的不同模块对性能的影响
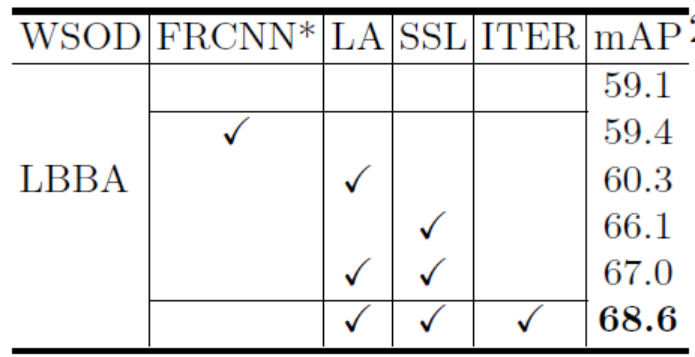
下表展示了迭代次数对模型性能的影响
单样本生成式域迁移旨在,在只使用一个参考图像的条件下,在只使用一个参考图像的条件下。然而,对于迁移后的生成器来说, (i) 生成类似于预训练生成器内容丰富的图像,同时 (ii) 忠实地获取目标域的参考图像的属性和样式。在本文中,我们介绍了一种新的单样本生成式域迁移方法,即 DiFa,用于多样的生成和准确的迁移。对于全局水平的迁移,我们利用差异参考图像的 CLIP 编码与源图像来约束目标生成器。对于局部适应,我们引入基于注意力机制的风格损失,它自适应的每个迁移图像块及其对应的参考图像块。为了更好的多样化生成,我么引入选择性跨域一致性来保持编辑隐空间中的域共享属性继承多样性预训练的生成器。大量实验表明我们的方法在量化和可视化上均达到了最优,特别是对于域间差距较大的庆幸。此外,我们的 DiFa 可以轻松扩展到零样本生成式域迁移任务中。

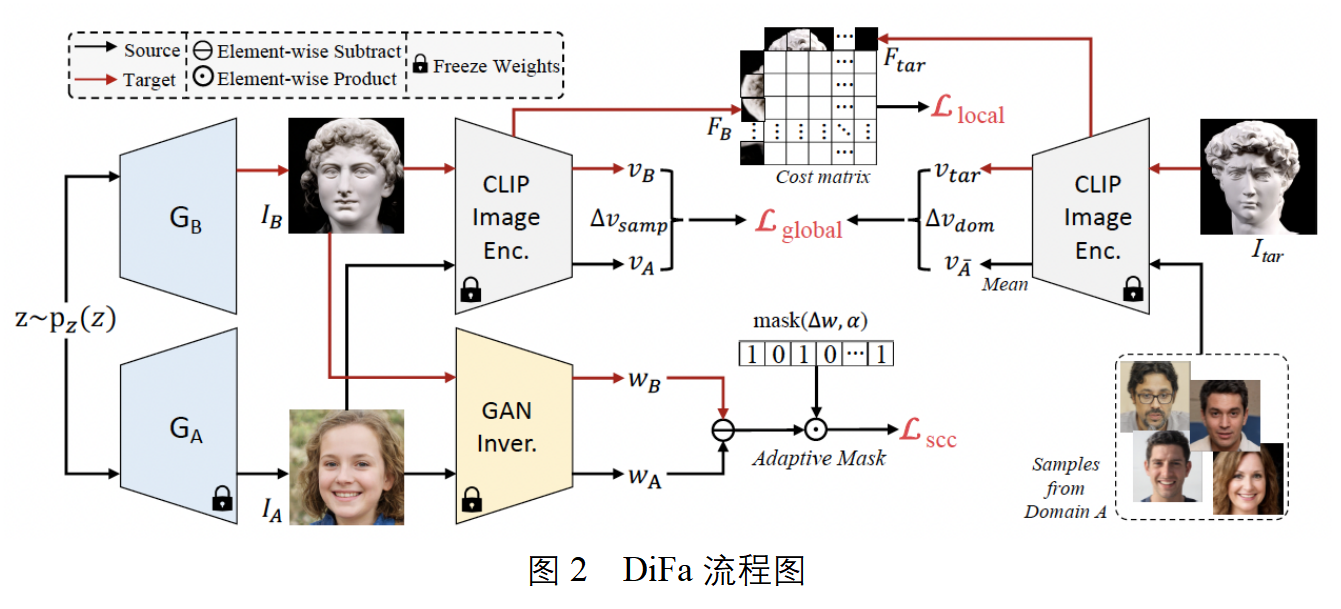
给定在源域A上预训练的生成器GA,以及来自目标域B的引导图Itar,首先使用CLIP编码器计算域间向量:
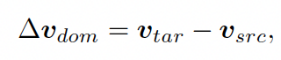
然后计算训练过程中样本间的偏移向量及全局损失函数
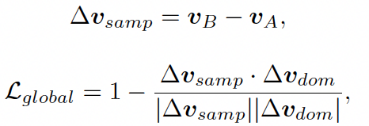
尽管域间向量可以捕获引导图中的全局水平的域代表性特征,而在CLIP编码空间中,局部属性和风格却经常被忽略。因此,只使用全局水平损失函数训练不能准确获取引导图中的局部信息。为了解决这个问题,我们提出了基于注意力机制的风格损失函数来帮助GB准确获取局部代表性特征。受风格迁移任务重风格-内容对齐的启发,我们设计局部损失函数,让迁移图中的每一块都能自适应的寻找并对齐引导图中的对应风格,损失函数如下所示:
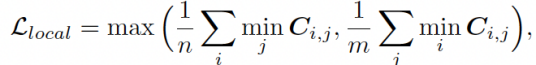
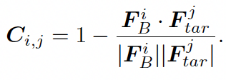
对于单样本生成式域迁移任务来说,生成多样的图片也十分重要。为了达到这个目的,我们首先把IA和IB均映射到隐空间,获取对应的隐编码。并在训练的过程中维持两个队列,分别存放来自域A和B的隐编码,并实时更新两个队列平均向量之差。根据这个差,计算自适应跨域一致性损失函数:
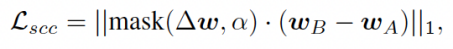
图3是本文提出的DiFa在源域为FFHQ和AFHQ-Cat,在目标域为不同引导图的可视化结果。表1是DiFa在源域为FFHQ和AFHQ-Cat,目标域为MetFaces和AFHQ-Wild的域迁移结果。从图3和表1可以看出,我们的方法在定量和定性方面均达到了最优。具体来说,Few-Shot Adaption产生了严重模式坍塌现象。StyleGAN-NADA不能准确的保持源域的属性,因此多样性较低。Mind The Gap对于域间差距较大的情况处理较差,有明显的瑕疵。

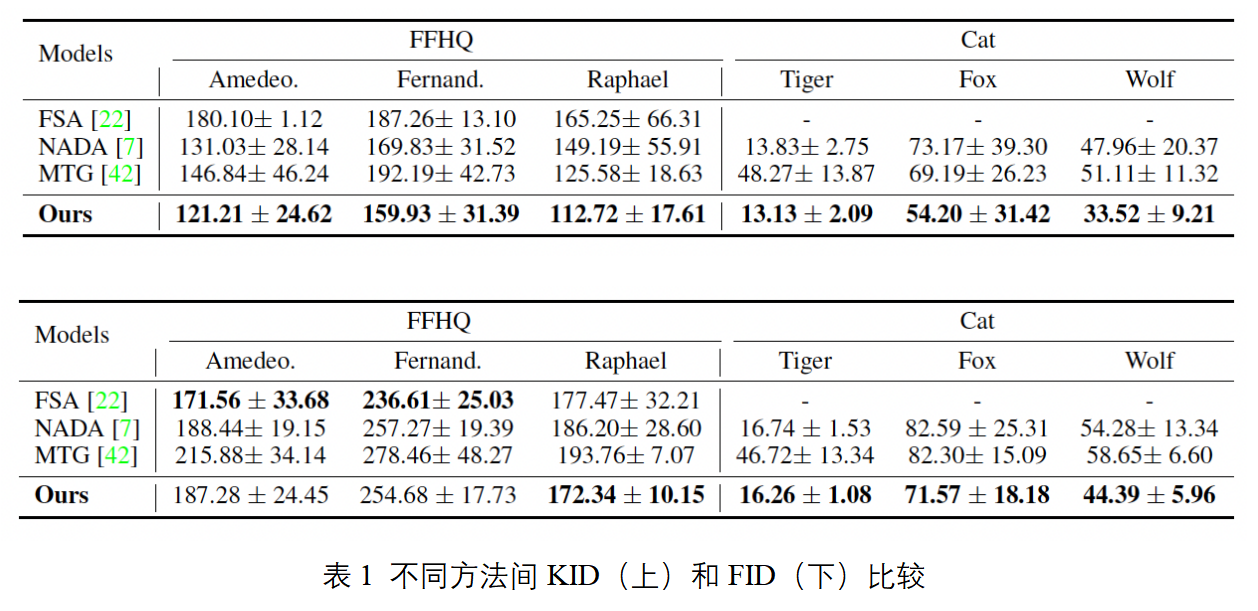
下表是对于两个主要损失函数SCC(Selective Cross-domain Consistency), AP(Attentive Style)的消融实验,能够比较直观地体现每个函数带来的性能提升。

视觉自注意力网络(ViTs)的少样本学习能力值得挖掘,但现阶段很少有相关工作探索这一问题。在本工作中,我们首先通过大量实验发现,基于相同的少样本学习框架,例如Meta-Baseline(ICCV 2021),直接将CNN特征提取器替换成一个ViT特征提取网络会带来严重的性能下降。进而,我们对这一问题进行了充分的分析,发现问题核心在于,由于缺少和CNN一样的归纳偏置,ViT通常会在少样本学习的训练范式下学到一些低质量的邻域区块相关性信息,这一点对于最终的少样本分类精度影响很大。为了解决这一问题,我们针对ViT,提出了一个简单但是有效的少样本分类训练框架Self-promoted sUpervisioN(SUN)。SUN首先在相应的少样本分类数据集上预训练一个ViT,并用其为每一组输入中的所有图像区块生成位置相关的监督信息,用来指导另一个相同结构的ViT的训练,使得新训练的ViT能够识别出相邻的区块是相同类别的还是不同类别的,从而促进邻域区块相关性的学习。引入这种稠密的监督信息能够有效改善ViT在少样本分类上的物体定位与识别能力,从而学到泛化能力更强的特征提取网络。为了进一步提升位置相关的监督信息的质量,我们引入了两个技术:背景过滤模块和空间对齐增广,从而进一步提升ViT在少样本分类上的效果。
本文的贡献如下:
(1) 分析了现有的多种ViT在少样本分类任务下的性能,并指出问题原因:缺少归纳偏置和低质量的邻域区块相关性学习效果。
(2) 为了改善ViT在少样本分类任务下的性能,我们提出了Self-promoted sUpervisioN (SUN),该方法主要通过引入来自相同数据集上预训练的教师模型输出的稠密标签,通过空间对齐增广和背景过滤模块进行增强,从而使得ViT学到一定程度的归纳偏置,并改善邻域区块相关性学习效果。
(3) 第一个针对多种ViT在少样本分类任务上进行分析并提出优化的解决方案的工作,为后续的少样本分类方法提供了一个简单但是足够可靠的基线方案。
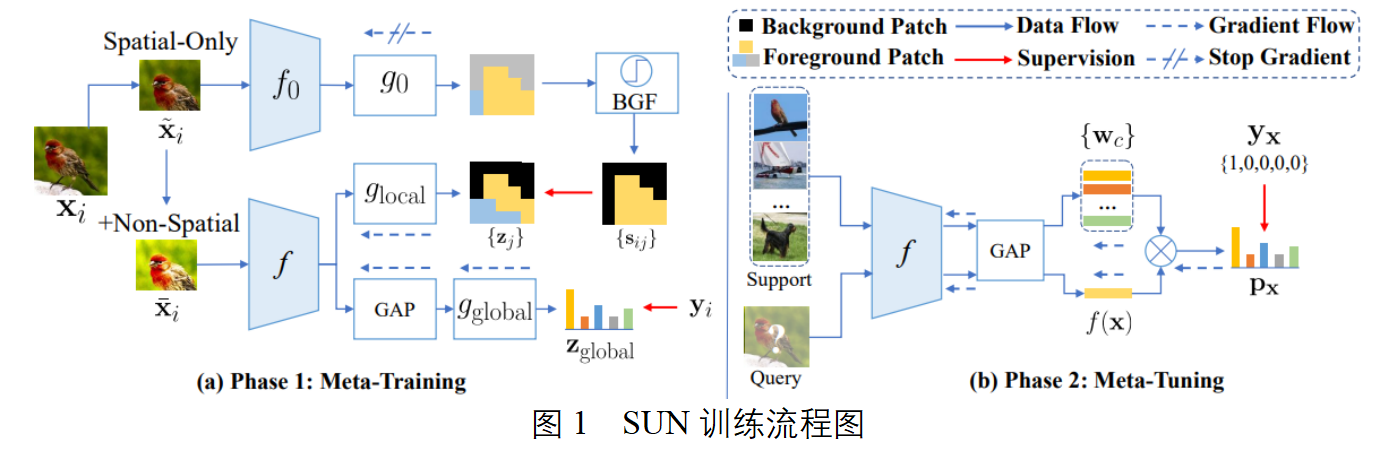
SUN的元训练阶段的目的是在训练集上学到一个特征表达能力较好,泛化性能较强的元学习器 f,使得 f 在开始元微调阶段前即拥有快速适应到新类别上的能力。 SUN的主要设计想法是引入一个来自在训练集上经过预训练的教师模型生成的位置相关稠密监督信息,目的是强化和加速图像区块邻域相关性的学习,从而能够提高在数据缺乏的条件下 ViT 的学习效率。具体来说,基于在训练集上预训练过的一个ViT,SUN首先为输入图像中的每个区块生成分类分数,如下所示。
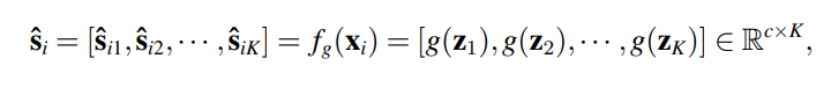
然后根据这个分数通过label smoothing的方法生成稠密的监督信息。该监督信息与原始的图像分类标签一起,用来训练一个结构相同的ViT,损失函数如下所示。
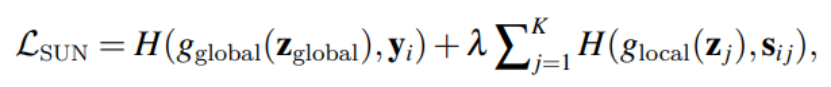
元微调阶段的目的是在训练集采样出的多个 “N-way K-shot” 任务上充分微调预训练好的元学习器 f,使得 f 能快速适配到仅有少数标注的新类别上。因此,不失一般性,我们选择引入多种简单但是有效的元微调策略来验证性能,例如 Meta-Baseline、FEAT 和 DeepEMD。
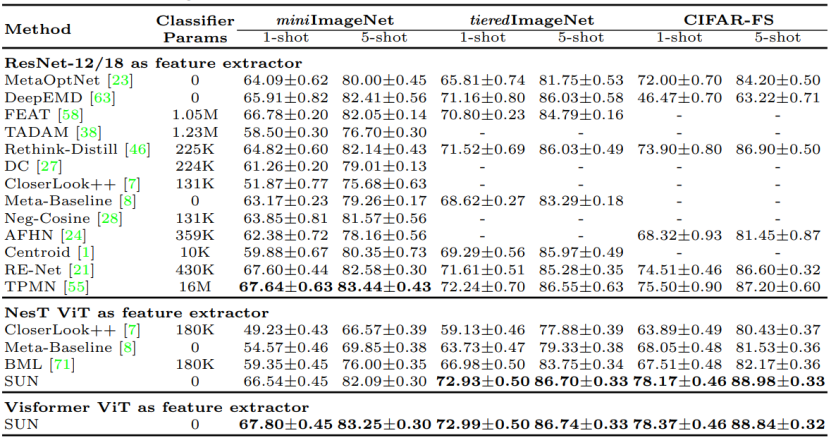
我们在miniImageNet,tieredImageNet和CIFAR-FS三种不同的少样本分类数据集上与之前的最优方法进行比较。需要注意的是以往的方法都是基于ResNet进行训练。如下表所示,我们的方法在三种不同的数据集上均达到了CNN-based方法的效果,说明SUN确实能够有效改善ViT在少样本分类上的性能。
我们对使用与不使用SUN训练的ViT抽取的特征进行了t-SNE可视化。与不使用SUN的ViT相比,使用SUN训练的ViT能够在新类别上抽出聚类效果更好的特征,说明SUN在少样本分类任务上提升了ViT的泛化能力。

我们针对SUN的几个核心模块进行了消融实验,以上所有模块对ViT的少样本分类都有促进效果。
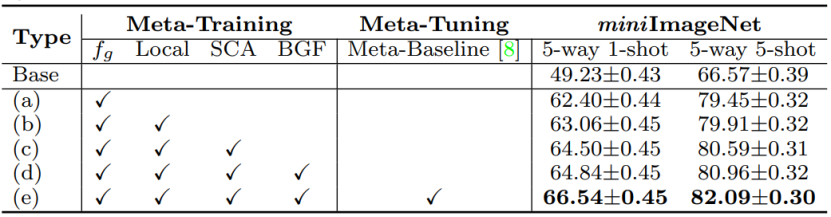
我们的SUN还可以与多种不同的少样本分类方法兼容,将其作为Meta-Tuning阶段,从而进一步提升性能。

不同于以往的CNN-based方法,SUN在更长的训练中收益更多。

图像盲复原任务由于退化类型复杂且无法有效模拟,导致现有方法性能提升有限。而人脸图像由于具有极强的结构性先验,每个人都拥有相似的眼睛、鼻子、和嘴结构,但是每个人又同时具有自己独特的结构信息(例如瞳孔颜色等)。对于人脸图像的盲复原,由于皮肤区域大部分趋于平滑,因此人们更关注于面部五官的复原效果。基于此,提出基于双记忆网络的人脸图像盲复原方法。通过在训练过程中,记忆和存储通用的五官结构特征以及身份相关的特定五官结构特征,用来引导任意低质量人脸图像的通用复原和特定复原过程。
本文的贡献如下:
(1)与现有方法直接学习从低质量到高质量的复原映射不同,本文通过外部学习的高质量特征字典来促进人脸图像盲复原过程;
(2)为了在一个框架中处理低质量图像既有引导图又无引导图的情况,本文提出学习通用字典存储人五官相似的结构特征以及特定字典存储当前身份相关的结构特征。每个人共享通用字典,且独有身份相关的特定字典。
(3)为了结合双记忆字典,本文提出字典迁移模块,能够有效利用双字典的优势,并且当引导图不存在时,也能够有效对人脸图像复原。
下图为DMDNet的整体流程图以及双记忆字典读取模块。
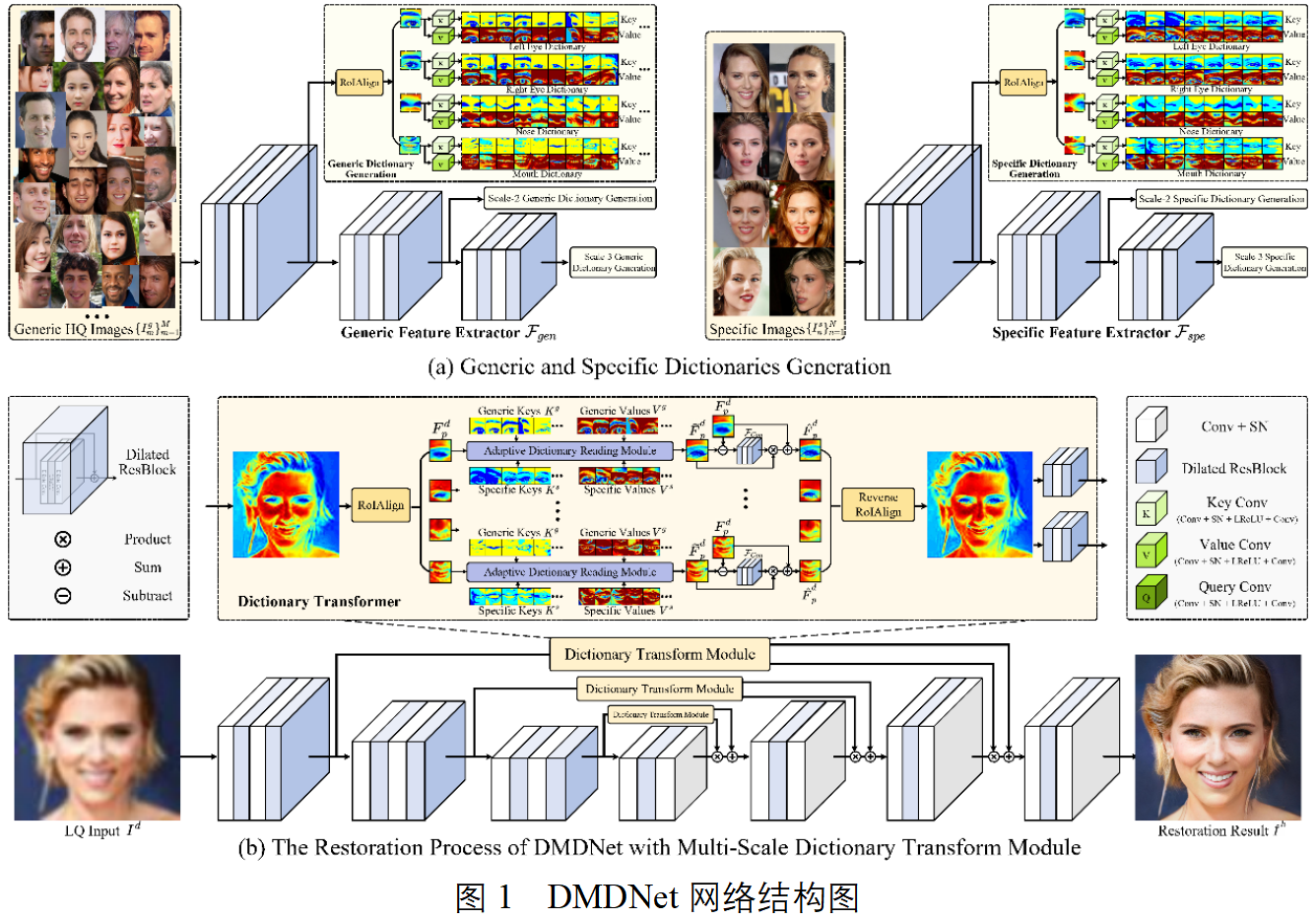
主要包含两个过程,1)字典构建过程:包含记忆任意身份的通用五官纹理的通用特征,以及身份相关的特定特征;2)引导复原过程:利用构建的字典,将记忆的特征引导任意低质量图像复原。当输入图像的引导图身份未知时,只利用通用特征即可进行复原。反之,若输入图像的身份已知并且具有多张高质量相同身份的人脸图像,通过网络提取身份相关的特定字典特征,结合通用字典特征,一同对其进行引导复原,在输入图像退化严重时,使得复原结果更像本人。
(a)字典的构建和优化过程为:
初始随机输入P张高质量通用人脸图像,对每一个通用特征字典构建P项通用字典项,每项通用字典项包含通用索引值和通用特征值;P为正整数;
对初始通用字典项前向更新:
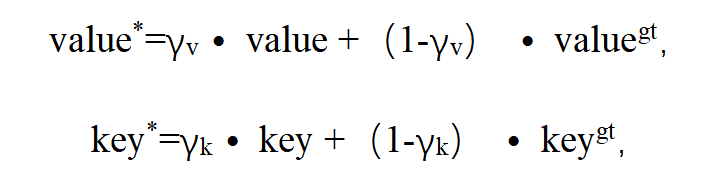
其中value*表示前向更新后的通用特征值,key*表示前向更新后的通用索引值;γv表示特征值可学习优化参数,γk表示索引值可学习优化参数,value表示已构建的通用特征值,key表示已构建的通用索引值,valuegt表示新输入高质量通用人脸图像的通用特征值,keygt表示新输入高质量通用人脸图像的通用索引值;
再对前向更新后通用字典项反向更新:
通过重建损失函数Lrec的梯度反向传播,对前向更新后通用字典项进一步优化,得到反向更新后最终通用字典项:
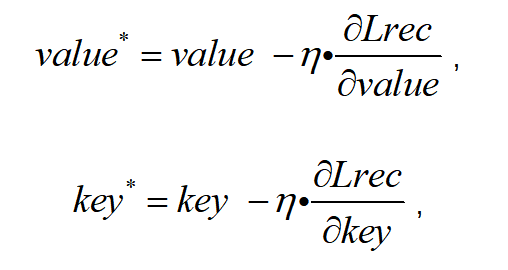
式中η表示学习率。
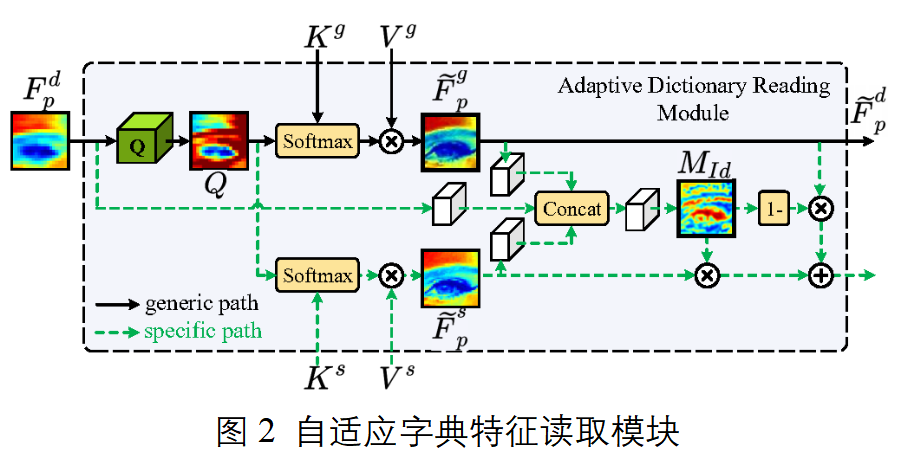
(b) 字典特征迁移模块
字典特征迁移模块获得遍历后字典特征的方法包括:
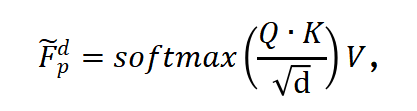
式中Fp为遍历后字典特征,Q为退化人脸部位特征的查询值,K为通用特征字典或特定特征字典的索引值,V为通用特征字典或特定特征字典的特征值,d表示常量。
此外设置置信度预测模块根据不同退化程度的输入对字典依赖程度不同,获得自适应融合特征的过程包括:
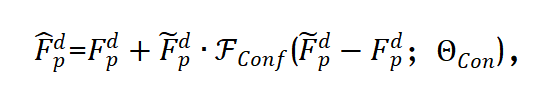
式中目标表示自适应融合特征,Fdp为退化人脸部位特征,Fconf为置信度预测网络,Θcon为置信度预测网络可学习参数;
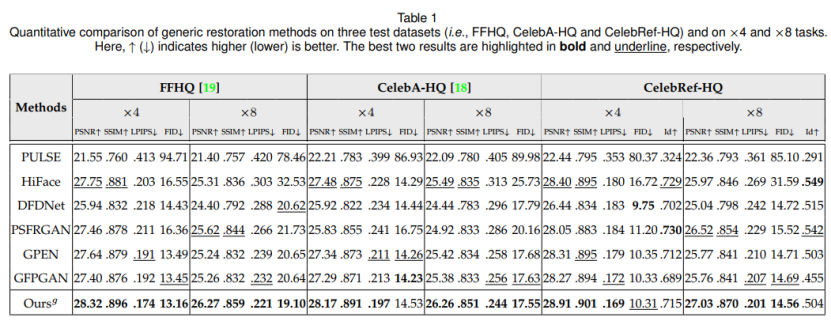
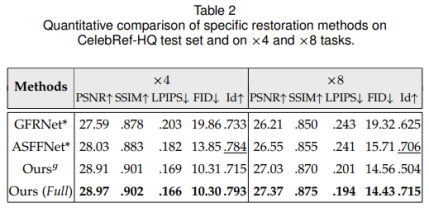
表1对比了本文通用复原方法(无同一人引导图)与现有方法比较结果,表2为特定复原方法(有同一人引导图)与现有方法对比结果。可以发现,只用通用字典的情况下,本文量化结果与其他对比方法均具有一定可比性,当引入同一人的特定字典时,从身份相关的量化结果看(Id项)复原效果会更接近本人。
下图为超分8倍的通用复原和特定复原效果对比。可以发现本文方法能够有效提升复原质量,当有引导图时,能够更好的保留与身份相关的特征(例如瞳孔颜色等)。

